2020-03-06 / 03월호 지면기사
/ 글│윤범진 기자 _ bjyun@autoelectronics.co.kr
IPU: New Hardware for “FOR THE AI”
영국의 스타트업 기업인 그래프코어(Graphcore)가 머신러닝(Machine learning, 기계학습) 워크로드를 실행하도록 설계된 IPU(Intelligence Processing Unit)라는 새로운 개념의 프로세서로 벤처캐피털(VC)과 유력 IT 기업으로부터 주목받고 있다. 그래프코어의 콜로서스(Colossus) IPU는 1,216개의 각 IPU 코어마다 프로세서 내 메모리 타일을 탑재했다. 지난 2월 그래프코어는 기자회견을 열고 한국 지사 설립을 공식 선언했다. 이날 기자회견에는 강민우 한국지사장을 비롯해 그래프코어의 파브리스 모이잔(Fabrice Moizan) 미국 영업 및 비즈니스 총괄 부사장이 참석했다.
글│윤범진 기자 _ bjyun@autoelectronics.co.kr
클라우드 기반 AI(데이터센터)의 경우, 현재 대부분의 컴퓨팅은 CPU나 GPU에 의해 제공된다. 그러나 AI 컴퓨팅의 성능 요구를 충족시키기 위해 칩 아키텍처가 크게 변화하고 있다.
이미지 처리는 신경망에 의해 효율적으로 처리되는 행렬과 관련된 병렬 작업이 필요하기 때문에, GPU가 전통적으로 신경망 구현에 매력적이었다. 반면, 기존 CPU는 AI 작업을 수행하도록 프로그래밍 할 수 있지만 동일한 연산을 실행하는데 더 오래 걸리고 더 많은 전력을 소비한다. 때문에 일각에서는 FPGA나 ASIC의 급성장을 점치기도 한다.
이미 IBM, 인텔, 퀄컴, 자일링스와 같은 반도체 회사들은 전력 효율을 개선하고 처리량(Throughput)을 향상시키기 위해 ASIC를 설계하고 있다. 이 회사들은 효율적으로 훈련될 수 있는 AI 칩 개발에 중점을 두고 있다. 이것은 학습할 수 있는 데이터를 공급하여 머신러닝 모델을 준비하는 단계다. 추론은 이미 훈련된 모델을 가져와서 유용한 예측을 하는데 사용하는 과정이다.
AI는 기존 프로세서 설계 회사들의 지배력을 와해시킬 수 있는 게임 체인징 기술로 부상하고 있다. 초기에 AI는 병렬 처리에 더 적합한 GPU로 이동하기 전에 CPU에서 구동했다. 여전히 GPU는 고밀도 부동소수점 연산에 뛰어나지만, 일부 업체들은 맞춤형 하드웨어로 더 높은 처리량과 에너지 효율을 보고했다. 상당수의 IT 회사들은 그들의 신경망 아키텍처 구현을 위해 CPU 대신 맞춤형 하드웨어를 선택했다. 집적회로(IC) 로직과 메모리 계층을 커스터마이징하면 이전 세대 GPU보다 훨씬 빠르고 에너지 효율이 높은 맞춤형 하드웨어 신경망을 생성할 수 있기 때문이다.
2017년 7월 중국은 오는 2030년까지 세계 1위의 AI 강국으로 도약하겠다는 ‘차세대 AI 발전 계획’을 발표했다. 화웨이(Huawei)는 서버 시장을 위한 새로운 AI 칩 ‘Ascend 910’을 비롯해 AI 학습 클러스터 ‘Atlas 900’을 공개했다. 또한 화웨이는 자체 스마트폰용 AI 칩셋인 ‘Kirin 990’를 발표했다. 알리바 바는 자사 최초의 자체 AI 칩 ‘Hanguang 800’을 발표했다. 호라이즌 로보틱스(Horizon Robotics)는 감시 카메라뿐만 아니라 자율주행 차량용 AI 칩 개발을 하고 있다. 이 회사는 최근 자체 개발한 ‘BPU(Brain Processing Unit)’ 아키텍처를 채용한 2세대 AI 칩 ‘Journey 2.0’을 발표했다. 미국에서는 인텔, IBM, 퀄컴, AMD, 엔비디아 등이 클라우드 AI 칩을 발표했거나 이미 공급 중이다. 클라우드 컴퓨팅 분야에서 입지를 강화하려는 구글, MS, 아마존과 같은 비 반도체 회사들도 클라우드용 AI 칩 개발에 대규모 투자를 하고 있다. 구글, 바이두, 알리바바와 같은 데이터 회사들뿐만 아니라 반도체 공룡 기업들 틈바구니에서 그래프코어와 같은 스타트업도 AI 칩 시장서 경쟁을 펼치고 있다.
현재 학습 부분은 엔비디아의 GPU가 주도하고 있으나, 구글이 ASIC의 한 형태인 자체 TPU(Tensor Processing Unit)를 개발함으로써 업계에 경쟁을 촉발했다. 사실 요즘 반도체 업계를 뜨겁게 달구고 있는 시장은 추론 부분이다. 추론은 클라우드 또는 엣지에서 실행할 수 있다. 기자가 주목한 그래프코어 IPU는 학습과 추론 모두 지원한다.
다음은 그래프코어 모이잔 총괄 부사장의 발표와 일문일답 전문이다.
 About Graphcore …
About Graphcore …
마치 예술 작품처럼 보이는 이 이미지는 계산 그래프 개념이 그래프코어의 그래프 프로세서(Colossus)와 그래프 프로그래밍 프레임 워크인 POPLAR(포플러)에 어떻게 매핑되는지를 보여줍니다. 강화학습(Reinforcement Learning)을 위한 신경망(Neural network)을 시각화한 이 이미지는 마치 사람의 뇌를 연상케 합니다. 머신러닝과 딥러닝(Deep learning, 심층학습)의 미래는 사람의 뇌처럼 활동할 것입니다. 때문에 저희는 계속해서 혁신을 도모하고 있습니다.
그래프코어는 AI 가속기 칩을 개발, 생산하고 있습니다. 저희는 이 그래프 프로세서를 IPU라고 부릅니다. IPU는 Intelligence Processing Unit, 즉 지능처리장치를 의미합니다. 이 프로세서와 함께 소프트웨어 스택(POPLAR)을 공급합니다. 또한 데이터센터와 서버에 사용되는 IPU 모듈과 시스템을 판매합니다.
그래프코어는 신생기업입니다. 그러나 지금까지 유수의 투자사와 기술기업으로부터 3억 1,000만 달러 이상의 투자 유치를 했습니다. 투자사로는 미국 벤처캐피탈 세콰이어 캐피탈을 비롯해 마이크로소프트(MS), BMW, 델(Dell), 삼성, 보쉬 등이 있습니다. 삼성으로부터도 투자를 받았기에, 오늘 이 자리에 있는 것이 아닌가 싶습니다. 삼성은 향후 AI 산업을 주도할 것으로 생각하며, 그래프코어의 주요 고객사이기도 합니다.
.jpg)
머신 인텔리전스(Machine Intelligence)의 진화 단계를 보면, 1단계는 단순히 물체를 인식(Object perception)하는 수준이었습니다. 현재 2단계에는 자연어 처리, 음성인식, 인터넷 검색 등에 적용되고 있습니다. 머신 러닝의 미래인 3단계는 과거를 학습함으로써 미래를 예측하게 될 것입니다. 현재 자율주행 차량은 단순히 이미지를 인식함으로써 의사결정을 내리게 되는데, 향후에는 과거 경험을 기반으로 주변 환경에서 어떤 일이 일어날지 예측하고 판단하는 완전 자율주행 차량으로 진화할 것입니다. 머신 러닝과 딥 러닝의 미래는 사람의 뇌처럼 사고하게 될 것입니다.
머신 러닝 워크로드를 실행하는 과정을 보면, 오래된 기술인 CPU를 사용하는 경우에는 전력 소모가 많습니다. GPU의 경우는 머신 러닝을 처리하는데 있어서 상당히 훌륭한 기술입니다. 하지만 대부분 그래픽적으로 치우쳐 있습니다. 때문에 지능을 처리함에 있어서 약간의 제약 요소가 있습니다. IPU를 설계한 이유가 여기에 있습니다. IPU는 향후 머신러닝이나 딥러닝에서 겪게 될 문제를 해결하는 데 집중하고 있습니다. 지금까지 다양한 프로세서가 소개됐지만 IPU는 사람의 뇌처럼 동작합니다. 저희는 그래프 기반의 기술이라는 점에서 사명(社名)을 그래프코어라고 했습니다.
그럼, IPU와 GPU는 어떻게 다를까요? 한 마디로 아키텍처가 다릅니다. 그래프코어 IPU는 그래프에 기반을 두고 있으며 동시에 여러 가지 문제를 해결할 수 있습니다. 또한 기존의 모델에 대해서 GPU 보다 월등한 성능으로 처리할 수 있습니다. 향후 미래의 기술에 대해서도 처리 능력이 훨씬 뛰어납니다. 현재 GPU로는 불가능하거나 생각하지 못했던 작업을 그래프코어 IPU를 통해 처리할 수 있습니다.
그래프코어 IPU의 효율성을 입증하기 위해, 자연어 처리를 위한 BERT 모델을 훈련(Training)에 적용에 봤습니다. BERT는 업계에서 검색 엔진이나 음성인식을 하는데 있어서 광범위하게 사용하는 언어 모델입니다. BERT 모델로 IPU를 평가했을 때, IPU가 GPU와 동등한 성능을 보이거나 어떤 경우에 더 뛰어난 성능을 나타냈습니다. 여기서 테스트한 것은 모델을 훈련하는 데 걸리는 시간입니다. 예를 들어, 자연어 처리를 함에 있어서 Wikipedia을 기반으로 해서 알고리즘을 완벽하게 하는 데까지 걸리는 시간을 테스트한 결과가 그림에 나와 있습니다.

똑같은 BERT 모델을 추론(Inference)에 적용해 테스트해 봤습니다. 예를 들어, 대개 구글이나 네이버 같은 검색 엔진을 통해 검색하게 되는데, IPU가 뛰어난 검색 결과를 나타냈습니다. 또 다른 사례로, 컴퓨터 비전을 들 수 있습니다. 지금까지 단순히 고양이를 탐지하는 것만으로도 괜찮았습니다. 하지만 이제는 HD 이미지를 활용하며 비디오 분석이 상당히 중요해졌습니다. 이런 상황에서, 새로운 모델에 대해서는 GPU가 올바른 기술이 아니라고 생각합니다. IPU가 이러한 새로운 모델에 대해서는 훨씬 뛰어납니다. 특히, 자율주행 차량에서도 마찬가지입니다.
일반적으로 자율주행 차량은 12개의 고화질(HD) 카메라를 장착합니다. 이밖에도 새로운 기술들을 요구하기 때문에 IPU가 적합합니다. 단순히 데이터센터나 자율주행 차량뿐만 아니라, 금융업계나 헬스케어 분야에서도 적용될 수 있습니다. 또 다른 사례로, 금융업계에서 사용하는 AI 모델로 MCMC(Markov Chain Monte Carlo) 확률 모델이 있습니다. MCMC 확률 모델을 훈련하는데 걸리는 시간이 IPU가 GPU보다 26배 빠릅니다.

현재 가장 큰 고객인 마이크로소프트(MS)가 작년 10월 최초로 IPU 기반의 서비스를 발표했습니다. MS 애저(Azure)의 경우, 스타트업에 투자한 사례가 없음에도 그래프코어의 장기 프로젝트에 투자했다는 점에서 상당히 놀라운 성과라고 할 수 있습니다. MS가 IPU를 선택한 이유는 고객에게 새로운 기술에 대해서 여러 가지 선택지를 제공하기 위해서입니다. 그래프코어 기술을 사용하기 원한다면 MS 애저를 활용하면 됩니다. 또한 서버 차원에서는 델을 사용하면 됩니다.
환상적인 하드웨어를 구동하기 위해서는 소프트웨어가 필요합니다. 현재 AI 플랫폼을 활용해서 모델을 개발하고 있는데, GPU를 사용하는 경우에 주로 많이 사용하는 플랫폼이 TensorFlow, ONNX, PyTorch입니다. 그래프코어 POPLAR라는 아주 간단한 소프트웨어 스택을 사용해 기존의 GPU 플랫폼에서 만든 모델을 최적화할 수 있습니다. 사용하기 쉽습니다. 추가적인 개발이 필요 없으며 상당히 간단하게 사용할 수 있는 소프트웨어입니다.
Questions & Answers
 Interviewee: Fabrice Moizan, GM & VP Sales US at Graphcore
Interviewee: Fabrice Moizan, GM & VP Sales US at Graphcore
Q. 지금까지 GPU가 AI 시장을 이끌어왔다는 점을 생각하면, GPU가 불가능한 작업이 무엇일지 상상하기 어렵다. 충분한 예를 들어 달라. 또한, 그래프 기반 아키텍처가 무슨 의미인지, 인메모리 프로세싱에 대해서도 자세히 설명해 달라.
A. 자연어처리 모델이나 영상처리 모델의 경우, 크기가 점점 더 방대해지고 있습니다. 최근 자연어처리와 관련해 GPT-2라는 대규모 번역 기반 언어 모델이 나왔는데. 이 모델은 15억 개의 파라미터를 가지고 있습니다. 현재 GPU 1천 개를 사용해 단지 모델 하나를 훈련할 수 있는 경우도 있습니다. 때문에 향후에는 모델을 마치 사람의 뇌처럼 학습할 필요가 있습니다. 이는 점차 데이터셋이 많아지고 대규모 데이터센터가 필요함을 의미합니다. 모델이 커지면서 훈련 시간도 점점 더 길어지고 있습니다. 어떤 경우에는 모델 하나를 훈련하는 데도 한 달이 소요됩니다.
데이터 과학자들은 혁신을 원합니다. 훈련 및 추론 시간을 단축할 수만 있다면 많은 긍정적인 혜택을 누릴 수 있습니다. IPU는 훈련 및 추론 시간을 훨씬 빠르게 해줍니다. 그래프코어 IPU는 프로세서에 직접 메모리를 배치했습니다. 따라서 프로세서와 메모리 간의 대기시간 보틀넥(latency bottleneck)을 없앨 수 있습니다. IPU는 학습 및 추론 모델을 메모리에 적재한 후 바로 연산할 수 있기 때문에 지연을 제거하고 연산 속도를 획기적으로 향상시켰습니다. 반면, GPU는 프로세서 외부에 메모리가 존재하기 때문에 대기시간 보틀넥을 피할 수 없습니다.
금융업계에서 사용하는 AI 모델인 MCMC(Markov Chain Monte Carlo) 확률 모델의 훈련에 IPU를 적용해 기존 프로세서로 2시간 이상 걸린 작업을 4분 30초 만에 최적화할 수 있었습니다. 대기시간이 길어지면, 트레이더들이 금융시장에 빠르게 개입하지 못하거나 즉각 반응하지 못하게 됩니다.
그래프코어는 기존 CPU나 GPU와는 전혀 다른 아키텍처를 사용합니다. GPU는 3D 렌더링을 위해 설계됐으며 상당히 많은 양의 픽셀을 동시에 처리합니다. 하지만 머신 러닝은 상당히 방대한 병렬처리에 기반하고 있습니다. 그래프코어 IPU는 ‘스파서티(sparsity, 희소성) 개념에도 잘 부합합니다. 스파서티는 무작위로 메모리에 액세스하는 것을 의미합니다. 어떤 애플리케이션은 여기저기서 끌어온 작은 데이터를 조합해 AI 모델을 구동하므로 방대한 양의 데이터가 필요 없습니다.
그래프코어의 콜로서스(Colossus) IPU에는 1,200개 이상의 프로세서 코어가 내장됩니다. 각각의 프로세서에는 256KB SRAM이 탑재돼 있습니다. 별도의 외부 메모리(DRAM)가 필요 없습니다. 이것이 기존 프로세서와 큰 차이점입니다.
GPU는 외장 메모리로 고대역폭 메모리(High Bandwith Memory, HBM)를 채택합니다. 외부에 있는 데이터를 끌어와야 하기 때문에 대기시간 문제를 야기할 수 있습니다. 메모리 대역폭이나 처리능력(Throughput)은 장점이나, 그 결과로 인해 전력소비가 증가할 수 있습니다.
IPU 프로세서 코어마다 짝을 이루고 있는 SRAM을 다른 프로세서가 사용할 수도 있습니다. 우리는 벌크 동기식 병렬(Bulk Synchronous Parallel, BSP)이라는 개념을 활용합니다. BSP 모델을 사용해 모든 IPU 프로세서 코어 간 통신을 지원합니다. 이는 각각의 프로세서가 동시에 계산 작업을 수행할 수 있다는 의미입니다(Computation, 로컬 계산 단계). 어떤 경우에는 프로세서가 연산을 중단하고 다른 프로세서와 동기화 작업을 실행합니다(BSP Sync, 동기화 단계). 또 다른 단계로 메모리를 교환하는 작업을 실행합니다(Exchange, 교환 단계). 이것은 정적(Static) 기반이기도 하지만 동시에 결정론적인 기반을 가지고 있습니다.[‘시간 결정성(time-deterministic)’, 즉 동기화 후 모든 교환이 특정 시간에 실행된다. 또 ‘그래프’의 ‘정적 특성(Static nature)’, 다시 말해 IPU에 의해 처리된 그래프는 일정 시간을 보장하기 위해 정적이어야 한다.]
Q. IPU가 CPU와 GPU를 모두 대체할 수 있다고 보나.
A. 그렇지 않습니다. CPU와 FPGA는 모두 훈련이 가능합니다. 또 GPU가 IPU보다 월등한 영역도 있습니다. 예를 들어, 아주 큰 이미지 관리에서는 GPU가 유리합니다. GPU는 상당히 큰 사이즈의 벡터(Vector, 디지털 데이터의 묶음) 구성으로 돼 있기 때문에 배치 사이즈가 큰 경우, 예를 들어 1,000개 정도의 배치 사이즈도 관리할 수 있습니다. GPU는 이미지 처리를 위해 설계됐기 때문에 영상의학 분야에서 유리하다고 할 수 있습니다. 반면, IPU는 배치(Batch) 사이즈가 작은 경우에 GPU보다 유리합니다. 또한 자연어 처리를 비롯해 데이터가 분산되어 있는 경우에도 IPU가 유리합니다.
Q. 가격 경쟁력은 충분한가.
A. 구체적인 프로세서 가격을 공개하기는 어렵지만, 가격 경쟁력은 뛰어나다고 할 수 있습니다. GPU와 비교해 가격적으로 문제없습니다. 예를 들어, 같은 가격에 엔비디아 PCI 카드에는 한 개의 GPU가 탑재되는 반면, 그래프코어 PCI 고속 카드 ‘C2’에는 두 개의 IPU(Colossus, 콜로서스)가 탑재됩니다.
Q. 국내 AI 시장 진출 전략은.
A. 그래프코어는 이제 막 한국지사 설립과 함께 한국시장에 진출했습니다. 큰 기대를 걸고 있기는 하나 1년 내에 시장점유율을 크게 높이기는 어려울 것입니다. 앞으로 강민우 지사장과 산하 팀원들이 한국 내 대학이나 연구소와 긴밀한 관계를 구축해 나아갈 것입니다. 한국은 혁신에 기반을 둔 국가라고 생각합니다. 한국에는 SKT, 카카오, 삼성, 네이버 등 다수의 혁신 기업이 있습니다. 이들 혁신 기업이 시장을 선도하기 원한다면, IPU가 제공하는 혁신을 활용하면 도움이 될 것입니다.
데이터센터가 보수적이라고 하는데, 지난해 MS는 클라우드 컴퓨팅 플랫폼 ‘애저(Azure)’에 그래프코어 IPU를 도입해 고객에게 좀 더 편리한 AI 개발환경을 제공한다고 발표했습니다. 우리는 2016년 설립된 신생기업이지만 MS가 그래프코어 IPU에 기반을 한 서비스를 출시한 것은, 고객들이 실용적이면서 혁신을 원한다는 사실을 알 수 있습니다.
Q. 자율주행 차량은 엣지 컴퓨팅의 대표적인 사례다. 엣지 컴퓨팅에서도 IPU를 적용할 수 있는 단계인가.
A. 자율주행 차량의 경우, 차내(In-vehicle) 솔루션을 주로 사용합니다. 이러한 솔루션에 IPU는 너무 크다는 인식이 지배적입니다. 그러나 IPU가 차내 영역에도 진입할 수 있다고 봅니다. 추론도 가능하고 아주 작은 규모로도 사용할 수 있습니다. 클라우드 상에서 모델 훈련에도 사용할 수 있습니다. 컴퓨터 비전이나 지각(Perception)에도 IPU를 사용하게 될 것입니다.
엣지 컴퓨팅의 경우, 1~20와트(W)의 저 전력을 사용합니다. 반면, 그래프코어 솔루션은 이보다 높은 75W의 전력을 소비합니다. 향후에는 엣지 컴퓨팅에서도 더 많은 연산을 요구하는 모델이 등장할 것입니다. 현재 저희가 가진 솔루션은 엣지 컴퓨팅 시장에는 맞지 않지만 2년 후에는 가능할 것입니다. 5G가 자동차 부문에서 상당한 지전이 이루어지고 있습니다. 때문에 2년 후 어떤 일이 일어날지 아무도 예측할 수 없습니다.
Q. Arm과 같이 (IPU) IP 코어 라이선스 모델을 구사할 계획이 있는가.
A. 없습니다. 그래프코어는 엔비디아처럼 프로세서 완제품을 판매하는 비즈니스 모델을 표방하고 있습니다. 첫 상용 제품은 대만 TSMC의 16나노미터 공정으로 제조됐습니다.
Q. 그래프코어가 추구하는 가치와 비전, 그리고 로드맵은.
A. ‘총소요비용(TCO)’과 ‘혁신’이라고 할 수 있습니다. 그래프코어는 칩 당 가격에 대해 언급하지 않습니다. 그다지 중요한 요소도 아닐뿐더러 데이터센터에서는 칩 당 가격이라는 하나의 요소보다는 TCO가 중요합니다. TCO 속에는 칩 가격도 포함되지만, 우리가 중요하게 보는 것은 동일한 IPU로 학습 및 추론 시간을 단축할 수 있다는 것입니다. 때문에 랙이나 서버 숫자도 줄이고 전력소비도 낮출 수 있습니다. 또 데이터 사이언티스트 입장에서는 결과를 훨씬 더 빨리 받아볼 수 있습니다. 이것이 그래프코어가 제공하는 가치입니다.
혁신은 대단히 중요합니다. IPU는 GPU로 구동이 불가능한 모델을 구동할 수 있습니다. 예컨대 MCMC 모델에서 추론을 함에 있어서 일부는 GPU와 FPGA를 사용하고 일부는 IPU를 활용할 수 있습니다. IPU는 의료공학이나 신약 개발에도 활용할 수 있습니다.
그래프코어 공동 창업자 두 분(나이젤 툰_Nigel Toon CEO, 사이먼 놀스_Simon Knowles CTO)은 기존 기술을 대체하기 위한 기술을 내놓겠다는 생각을 하지 않았습니다. 그래프코어는 기술을 개발할 때, 오늘날 존재하는 문제를 해결하기 위한 솔루션이 아니라, 향후 10년 동안 발생할 수 있는 문제를 해결할 수 있는 기술을 개발하자는 차원에서 접근했습니다. 향후 10년 동안 어떤 문제가 발생할지 아무도 알 수 없습니다.
그래프코어는 애초부터 GPU를 대체하자는 차원에서 회사를 설립한 것이 아닙니다. 기존에 없던 새로운 기술과 혁신적인 방식을 통해서 문제를 해결하고자 했습니다. 전 세계의 영향력 있는 업계 전문가들을 만나 머신 러닝과 딥 러닝 관련해서 어떤 문제가 있는지를 이해했고, 상당히 오랫동안 건재할 수 있는 아키텍처를 구축하기 원했습니다. 그 결과물로 ‘온칩 메모리’라는 아이디가 나온 것입니다. 온칩 메모리를 통해서 처리능력을 향상시키고 대기시간을 최적화할 수 있었습니다.
2년 전, 시장이 역동적으로 진화하면서 ‘스케일아웃(Scale-out)’이라는 단어를 많이 사용하게 됐는데, 현재 8개 IPU나 16개 IPU만을 연결하는 것이 아니라 수천, 수만 개의 IPU를 연결할 수 있을 정도로 변화가 빠르게 일어나고 있습니다.
당연히 로드맵이 있습니다. 많은 투자자들이 그래프코어 로드맵을 보고 투자를 결정한 것입니다. 6개월 내에 그래프코어 관련 소식을 많이 접하게 될 것입니다.
Q. 2021년에 AI 칩 업체 중 절반이 사라질 것이라는 전망도 있다.
A. AI를 ‘빅오션(Big ocean)’이라고들 합니다. 응용분야가 많다는 의미겠죠. 스마트폰 자체도 하나의 AI라고 할 수 있습니다. 엣지 단에서 사용하는 AI도 있습니다. 반면, 고성능 AI도 있습니다. 예를 들어, 추론 분야에서는 50개 정도의 회사가 활동하고 있습니다. 현재 고성능 AI 분야에서, 학습 및 추론을 모두 할 수 있는 회사는 엔비디아, 구글, 그래프코어뿐입니다. 그만큼 학습과 추론을 모두 할 수 있는 AI 칩을 개발하기가 어렵습니다. 소프트웨어 또한 상당히 복잡합니다. 인텔은 AI 칩 너바나(Nervana) 개발을 중단하고 (하바나 랩스의 AI 가속기) 하바나(Goya와 Gaudi)에 주력할 것이라고 발표했습니다. 반면, 우리는 혁신을 실현할 수 있는 영역에 집중하고 있습니다.
많은 AI 칩 회사들이 이미 사라졌습니다. 때문에 어떤 회사가 AI 칩을 구매할 수 있는 여력이 있는가를 봐야 합니다. 그래프코어는 하이퍼스케일 데이터센터나 클라우드 서비스 회사가 빅바이어라고 생각합니다. 빅바이어로는 AWS(아마존웹서비스), MS 애저, 알리바바 등을 꼽을 수 있습니다. 운 좋게도 그래프코어는 MS 애저로부터 투자를 받았습니다.
Graphcore Colossus IPU(GC2)의 특징
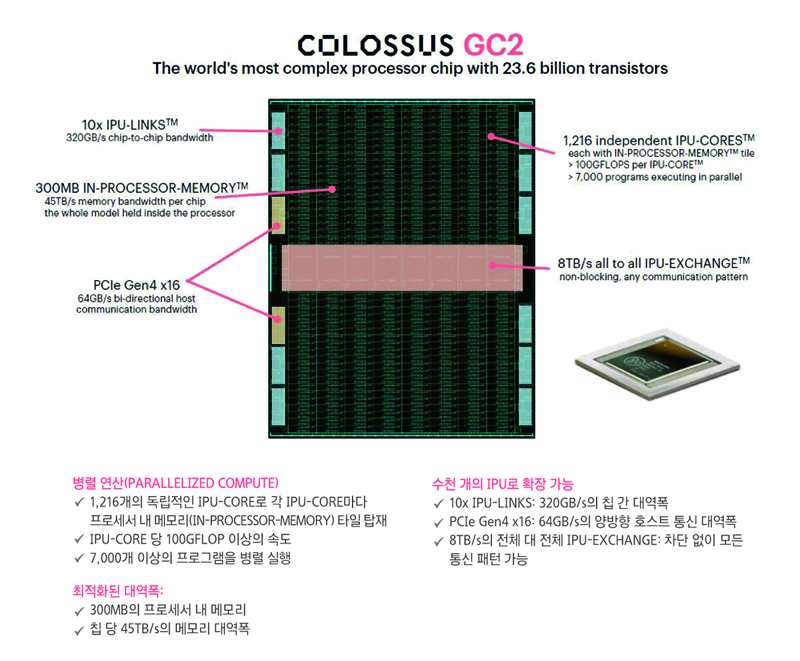
IPU는 대규모 병렬(Parallel) 및 동형(Homogeneous) 멀티코어 아키텍처를 사용한다. 가장 기본적인 하드웨어 처리장치는 IPU 코어로, 동시에 6개의 스레드를 실행할 수 있는 동시 멀티스레딩(Simultaneous Multi-Threading, SMT) 프로세서다. GPU의 SIMD/SIMT 아키텍처보다 멀티스레드 CPU에 더 가깝다고 할 수 있다. 2018년 출시된 첫 상용 제품인 ‘콜로서스(Colossus) GC2 IPU’는 1,216개의 독립적인 IPU 코어와 각 IPU 코어마다 프로세서 내 메모리(256KB SRAM) 타일을 탑재했다. 따라서 IPU 칩은 약 300 MB의 온칩 메모리를 포함하고 있다. IPU의 칩 당 메모리 대역폭은 45 TB/s이다. IPU 코어 당 최대 100 GFLOPS(1 GFLOP은 초 당 약 10억 부동소수점 연산에 해당) 이상으로 300 MB 메모리와 짝을 이뤄 최대 1만 개의 프로그램을 병렬로 실행할 수 있다.
IPU 타일을 연결하는 상호연결 메커니즘을 IPU-Exchange라고 하는데, 8 TB/s의 총 대역폭으로 차단 없이 모든 통신 패턴을 실현할 수 있다. IPU-Link는 320 GB/s의 칩 간 대역폭으로 상호연결을 가능하게 하며, PCIe는 64 GB/s의 양방향 호스트 통신 대역폭을 제공한다.
IPU는 벌크 동기식 병렬(Bulk Synchronous Parallel, BSP)이라는 병렬 컴퓨팅을 위한 소프트웨어 브리징 모델을 사용한다.
그래프코어의 소프트웨어 스택 POPLAR®는 구글에서 만든 텐서플로(TensorFlow) 프레임워크와 호환 가능한 AI 모델 생태계 ONNX와 통합됐다. 페이스북 파이토치(PyTorch)와 호환도 올초까지 완료한다는 계획이다. <끝>
AEM(오토모티브일렉트로닉스매거진)
<저작권자 © AEM. 무단전재 및 재배포 금지>




 PDF 원문보기
PDF 원문보기
