


전자제어장치(ECU) 개발
지난 섹션에서 설명했던 것과 같이 회사 스타일 가이드라인과 자동 검사자가 준비되었으면 ECU를 개발해야 한다. ECU를 개발하는 초기 과정에서 모델은 연구 단계에서 벗어나 정식으로 소프트웨어를 개발하는 데 쓰이게 된다. 이러한 과정은 모델이 구체화되기 시작하는 시점이며, 검사와 버전 제어와 같은 개발 작업들이 자주 나타나는 시점이다. 초기의 모델은 배정밀(double precision) 부동소수점 데스크톱 시뮬레이션과 같은 이상적인 환경 안에서 시스템 동작을 정립하고 평가하는 데 초점을 맞추고 있다. 나중에 동작 특성은 구체화되고 제약을 받아 생성된 코드가 16비트 고정소수점 마이크로컨트롤러와 같은 양산 환경에서 적절하게 작동할 수 있도록 한다.
양산 코드 생성 과정은 다음과 같다.
1. 동작 특성 모델을 생성하고 가이드라인을 따르고 있는지 점검한다.
2. 고정소수점 scaling과 calibration을 포함하여 데이터를 정의한다.
3. 필요한 기존 코드나 외부 코드를 통합한다.
4. 특정 양산 ECU에 맞는 코드를 생성하고 배치하기 위해 모델을 설정한다.
5. 코드를 생성하고 검사하며 프로파일 한다.
6. 2에서 5단계를 반복하며 필요한 만큼 최적화한다.
1단계: 동작 특성 모델 생성
이 단계에서 모델 스타일 가이드라인은 동작 특성 모델이 정밀한 설계와 생성 코드로 변환될 수 있도록 도와준다. 이 부분에서 주의해야 할 몇 가지 부가적이거나 기본적인 가이드라인은 다음과 같다.
Descrete, Fixed-step 모델을 사용하라
시스템 모델은 센서, 액추에이터, ECU(혹은 애플리케이션), 플랜트(혹은 환경)으로 구성된다. 동작 모델은 continuous-time과 variable-step을 사용하여 시스템을 만들고 시뮬레이션한다. 이는 센서, 액추에이터, 그리고 플랜트의 입력과 출력 관계가 연속적이거나 아날로그적인 방식(즉, 엔진 온도)으로 작동하는 비디지털 환경 안에 존재하기 때문이다. 이러한 관계들은 연속적인 블록과 variable-step을 통해 최적으로 모델링된다. 그러나 ECU는 그것이 fixed-step 인크리먼트 안에서 discrete 시간을 쓰기 때문에 예외이다.
초기에 컨트롤러 모델을 discrete하고 fixed-step 환경으로 바꾸는 것은 시간을 절약하고 추후에 반복 작업으로 인한 번거로움을 줄여준다. Simulink 컨트롤 설계는 continuous 모델을 자동적으로 discrete 모델로 변환해주는 Model Discretizer를 포함한다. 이때 개발자들은 Sample rate와 변환 방법(주로 pre-wrap이 포함되거나 포함되지 않은 Tustin이 사용됨)을 구체화해야 할 필요가 있다.
리얼타임 워크샵 임베디드 코더는 continuous time 블록을 지원한다. 이것은 시뮬레이션 가속화와 래피드 프로토타이핑에는 좋을지 모르지만, 양산 코드를 만들 때는 discrete 블록을 사용하는 것이 좋다. 또한 코드는 래피드 시뮬레이션 타깃(Rapid Simulation Target)을 사용하여 variable-step solver로도 생성시킬 수 있다. RSIM은 시뮬레이션 가속화, monte Carlo 연구, 그리고 일괄 실행에 유용하다.
만일 적절하다면 상태 기계 대신 스테이트플로우 진리표를 사용하라
진리표는 스테이트플로우의 새롭고 중요한 구성분이다. 이는 Boolean 컨디션의 세트를 만드는 행동을 도식화하고 복잡한 결정을 내릴 때 state가 없는 논리를 명백하게 구체화하는 간단한 방법을 제공하며, state가 없는 모드 논리와 같은 애플리케이션에 특히 유용하다. 사실 진리표는 스테이트플로우에서 상태 기계를 사용하여 이미 설계되었을 복잡한 논리 행동에 명쾌한 복합 논리 해결 방안을 제시한다. 진리표를 사용하는 이점 중 하나는 천이 논리처럼 상태 기계의 세부 사항을 저장하는 불필요한 과정이 없다는 점이다. 또한 스테이트플로우 진리표는 이해하기 쉽고, 논리적인 완성도를 점검하는 자동화 분석 기능을 가지고 있다.
그림 5는 엔진 작동 모드를 기반으로 한 연료 세팅을 계산하는 진리표를 보여준다. 도표의 맨 위 부분은 Boolean 컨디션의 특별한 세트를 위한 행동을 지정하는 컨디션 테이블을 보여준다. 도표의 아래 부분은 수행되어야 할 행동 양식을 보여준다.
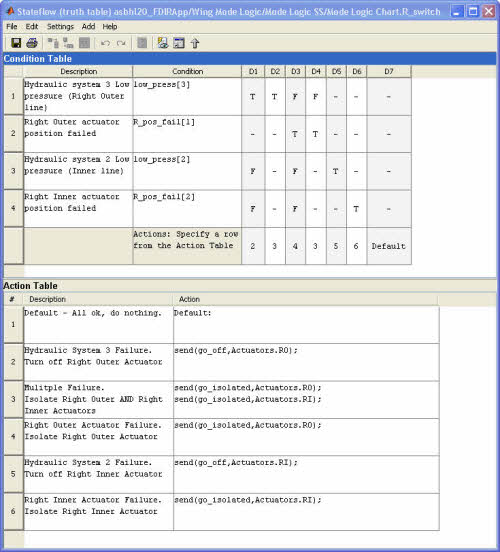
[그림 5] 연료 선택 논리 구현을 위한 초기 진리표 디자인
유효한 진리표는 컨디션 열의 각 행이 다른 행과 독립적으로 참이거나 거짓이어야 한다. 이때 그림 6에서 보는 것처럼 스테이트플로우에서 진리표가 유효한지 점검하는 진단 프로그램을 실행시킬 수 있다.

[그림 6] 고정소수점과 부동소수점 코드의 비스테온 결과
전사적인 모델링 고려사항
모델 가이드라인은 대규모 혹은 복잡한 프로젝트에 특히 유용하다. 이러한 전사적인 프로젝트에서는 다양한 사용자와 장소의 모델링 환경을 가장 효과적으로 관리하는 방법과 같은 부가적인 개발 문제를 계획하고 설명하는 것이 중요하다.
몇몇 기준들은 대규모 모델을 관리하는 설명 전략과 마찬가지로 프로젝트가 전사적 차원에서 이뤄지는 것인지 결정할 수 있도록 정립되어 왔다1.
애플리케이션은 다음 상황에서 전사적 차원일 것이다.
● 한 사람이 모든 사항을 알기에 모델은 너무 크다. 적어도 10,000개 블록이 있으며, 10개 이상의 고객 라이브러리(custom libraries)에 연결되어 있다.
● 많은 팀 멤버들은 다양한 구성 부품과 함께 가장 상위 레벨의 모델을 공유한다. 한 디자인을 위해 5명 이상의 엔지니어가 협력하며, 15명 이상의 엔지니어가 동일한 모델을 공유한다.
● 한 조직 안의 많은 팀들은 재사용할 수 있는 구성 부품들을 공유한다. 20개 이상의 실제 사용되고 있는 설정 제어 모델이 있으며, 큰 디자인의 다양한 활성화된 릴리즈들이 있다. 또한 모델 기반 설계를 지원하는 팀이 있다.
MATLAB 안에서의 필요한 Simulink 진단 명령인 Sldiagnostics는 모델 사이즈를 결정하는 데 도움을 주는 툴이다.
인보케이션 콜(invocation call)과 그 결과들의 예는 다음과 같다.
>>[txt,dat]=sldiagnostics(‘fuelsys’,’CountBlocks’)
fuelsys Total blocks : 258
Clock : 1
Constant : 31
DataTypeConversion : 1
Demux : 4
…
‘Libs’ 옵션들은 사용된 라이브러리 숫자를 목록으로 만들기 때문에 유용하다.
Model 블록들을 사용하는 것 같은 대규모 모델을 관리하는 여러 가지 기능들은 매스웍스 릴리즈 14에서 이용할 수 있는 데, 이는 다른 모델을 참조하는 블록들을 가진 모체 모델(parent model)을 만든다. 근본적으로 이러한 모델을 참조하는 접근 방법은 개발자들이 모델 기반 설계와 함께 구성 부품 기반 구조를 쓸 수 있게 해 준다.
Model 블록은 여러 가지 다른 전사적 이슈들을 가능케 한다.
● Model 블록에 의해 참조되는 모델은 그것을 참조하는 모델과 완전히 분리된 파일이며 설정 아이템이기 때문에 설정 관리를 향상시킨다.
● 로드와 업데이트, 시뮬레이션 속도를 향상시킨다. 모델은 복사되지 않고 참조되어 필요한 경우에만 메모리에 로드되기 때문이다.
● 변화된 부분이 있을 때만 코드를 재생성 한다. 이는 코드가 만들어지는 시간을 줄여 주고, 한 모델의 변화가 다른 모델로의 영향을 최소화하기 때문이다.
위의 마지막 아이템은 특히 이미 검증된 양산 코드를 업데이트하거나 유지하는 동안 기존의 것까지 소급하여 테스트하는 것을 최소화하는데 특히 유용하다.
버스 오브젝트(Bus Object)는 전사적인 모델의 모델링을 도와주는 ‘릴리즈 14’의 또 다른 아이템이다. 개발자들은 구성 요소들 간의 인터페이스를 제어하는 데(ICD) 버스 오브젝트를 사용한다. 표본 인터페이스는 실수, 정수, boolean과 같은 다양한 데이터 타입의 변환된 데이터 리스트를 가지고 있을 것이다. 비가상적인 버스 오브젝트는 코드 생성을 지원하며 생성된 양산 코드 안에서 C struct로 변환된다.
2단계: 데이터 정의
동작 특성 모델이 만들어 진 후 ECU 개발 작업은 구현에 좀 더 초점을 맞추게 된다. 고정소수점 데이터 타입 사용을 포함하여 정밀한 데이터 타입을 정의하는 것은 이 단계의 중요한 작업이다. Simulink의 모델 익스플로러는 Simulink와 스테이트플로우 데이터를 포함한 데이터 사전을 개발하고 살펴보며 관리할 수 있도록 한다.
다양한 임베디드 마이크로프로세서에 적용시키기에 유용한 모델링 스타일은 Simulink 모델2과는 별도로 로드되고 저장된 다양한 데이터 사전을 만들어 주는 것이다. 블록의 설정 파라미터는 그림 6에서 보는 바와 같이 생성된 코드의 효율성에 중요한 영향을 미친다.
벤치마크 결과에서 보는 바와 같이 Simulink에 설치된 단일 오버플로우/언더플로우를 사용하는 것은 고정소수점 생성 코드가 더 크거나 작거나 수동 코드와 거의 비슷한 경우에 Simulink 안의 파라미터 세팅을 차단한다. 이 과정은 모델링 스타일이 생성된 코드3에 얼마나 영향을 주는지 그 중요성을 이해하는 데 결정적인 증거가 된다.
이전에 논의했던 것과 같이 모델 어드바이저가 고정소수점 팁 안에서 확인된 몇몇 경우를 포함한 여러 가지를 점검한다는 것을 유념해야 한다. 또한 Simulink Fixed Point는 고정소수점을 부동소수점으로 바꾸는 것을 도와주는 자동 스케일링 도구들을 포함하고 있다.
3단계: 기존 코드 통합
기존 코드 혹은 외부 코드를 통합하는 것은 양산 코드 생성에서 중요한 부분이다. 자동 생성 코드로부터 불러와야 하는 양산성이 입증된 재사용 코드의 양이 많은 경우도 종종 있다. 이 문제의 전형적인 예는 양산 조직의 최적화된 lookup 테이블을 불러오는 것인데, 적절하게 형성된 데이터 정의와 메모리 위치가 필요하다. Simulink는 기존 코드를 포함하기 위하여 몇 가지 메커니즘을 가지고 있지만 양산 환경에 가장 많이 쓰이는 것은 S-function을 만드는 것이다. 특별한 데이터 정의는 custom storage class를 사용하여 수행할 수 있다. S-function 블록은 시뮬레이션을 할 동안 기존 코드 기능을 불러올 수 있게 하며, 생성된 코드 안에서 함수를 호출하는 코드를 생성한다.
S-function을 생성하는 기존의 방법은 다음과 같다.
● 스테이트플로우: 사용자 제공 함수 호출과 연동(include 파일)로부터 S-function을 자동적으로 생성하여 기존 코드를 쉽게 불러온다.
● S-function Builder: Simulink 안에서 최소한의 사용자 제공 정보를 사용하여 그래픽으로 S-function을 만든다.
● 수동 생성 S-function: S-function을 만드는 가장 유동적인 방법이지만 가장 많은 지식이 필요하다.
Legacy Code Tool은 Simulink에서 S-Function을 생성하는 새로운 방법으로 시뮬레이션 및 코드를 생성하기 위해 기존의 코드를 통합하는 가장 쉽고 빠른 방법이다. 개발자들은 단지 함수 호출 인터페이스와 필요한 파일들만 정의해주면 Legacy Code Tool이 자동적으로 S-Function을 생성시켜 준다.
수동으로 S-function을 만드는 데 추천할 만한 몇 가지 스타일은 다음과 같다.
● 간단한 S-function 템플릿부터 시작한다.
● 적용할 수 있는 경우에는 입력과 출력을 재사용할 수 있고 로컬로 지정할 수 있도록 S-function을 설정한다.
● 적용할 수 있는 경우에는 S-function의 입력과 출력에 대하여 expression folding이 가능하도록 한다.
위의 추천안들은 가능한 한 임시 변수와 과잉 계산을 제거함으로써 ROM과 스택 사이즈를 줄일 것이다. 위에서 언급한 기존 lookup 테이블을 사용하게 되면 생성되는 양산 파일럿 프로그램에서 전체 애플리케이션의 30% 정도의 RAM을 절약할 수 있게 된다. 다른 가능한 옵션들에 대한 자세한 사항과 제한 조건들은 S-function 문서를 참조하면 된다.
4단계: 코드 생성을 위한 모델 설정
상세하고 적합한 데이터 정의와 기존 코드를 포함하여 모델이 만들어지면 양산 코드를 생성할 수 있다. 그러나 더욱 최적화된 코드를 만들기 위해 다양한 코드 생성 옵션들을 이해하고 확인하는 것이 중요하다. 예를 들어, enable local block outputs의 옵션이 선택되지 않으면 모든 중간 신호가 글로벌 데이터로 정의될 수 있기 때문에 잠재적으로 RAM의 사용을 두 배 이상으로 만들 수 있다.
Simulink에서 코드를 생성하는 여러 가지 옵션은 모델 익스플로러 안에서 통합되며 설정 세트로 저장된다. 모델은 다양한 설정 세트를 가질 수 있지만, 단 하나의 설정 세트만이 활성화될 수 있다. 설정 세트들은 모델과 함께 저장되거나 독립적으로 저장될 수 있다.
일반적인 스타일은 모델과 연관된 다양한 설정 세트를 갖는 것이다. 모델 기반 설계 작업 흐름 안에서 필요한 ECU 프로그램에 따라 적절한 설정 세트가 활성화된다.
예를 들면, 하나의 모델이 다음과 같은 설정 셋 옵션들을 가질 수 있다.
● Rapid_Prototyping_Config
● On_Target_Rapid_Prototyping_Config
● Production_Code_ANSIC_Config
● Production_Code_TargetSpecific_Config
● Software_In_Loop_Config
● Processor_In_Loop_Config
● Hardware_In_Loop_Config
이와 같은 경우에는 하나의 코드 생성기를 사용하는 모델 안에 여러 가지 목표를 위한 다양한 설정 셋이 있을 수 있다.
최적화된 설정으로 결과를 얻는 가장 빠른 방법은 리얼타임 워크샵 임베디드 코더 블록 라이브러리에서 제공되는 Configuration Wizard 블록을 사용하는 것이다.
Configuration Wizard 블록을 모델에 추가하고 더블클릭하면 사용할 수 있다. M-file 스크립트는 수동으로 조정할 필요 없이 모델의 활성화된 설정 세트 안에서 미리 지정된 옵션으로 설정된다. 예제 M-file 스크립트와 통합할 수 있고 양산 프로그램 요구를 수용할 수 있는 custom 블록 또한 존재한다.
소프트웨어 조직들은 반드시 특정한 설정 세트를 정립하고 이를 양산 프로그램의 수명 주기 동안 지속적으로 사용해야 한다. 이는 코드 컴파일러의 세팅이 구축되고 기준화되는 방식과 유사하다.
5단계: 생성-검증-최적화
ECU 개발 과정의 마지막 단계는 코드를 생성하는 것과 그 성능을 평가하는 것이다.
이 평가를 돕기 위해 개발자들은 Link for TASKING™과 같은 제품을 사용할 수 있다. 이 제품, 그리고 다른 임베디드 타깃 제품들은 RAM/ROM/STACK 리포트를 자동으로 생성시키고 프로그램 실행을 자동화하며 Simulink와 타깃 프로세서(Tricore, ARM, ST10 및 Altium TASKING에 의해 지원되는 기타 프로세서)를 이용하여 Processor-in-Loop 시뮬레이션을 가능하게 한다. PIL 비교 차트의 한 예는 그림 7에서 보는 바와 같다.
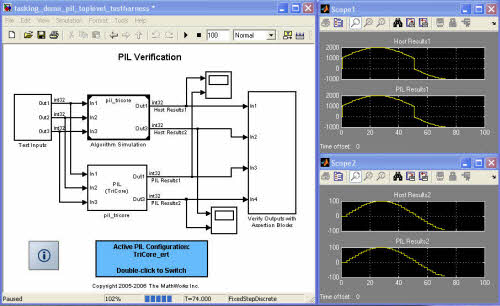
[그림 7] Link for TASKING을 이용한 PIL co-plot의 예
RAM과 ROM, 그리고 실행 속도와 수치 결과가 프로그램의 목표에 적절한 지를 결정하는 것은 개발자들과 프로그램 관리에 달렸다. 그렇지 않을 경우, 단계 2로 되돌아가 특성 모델에 최적화된 새로운 레이어와 그에 따른 조사가 필요하다.
결론
필자는 본지를 통해 양산 코드를 생성할 시 모델 기반 설계를 적용하기 위한 모델 스타일 가이드라인을 제시했다. 이 과정에서 양산 구성 모델을 돕고 명확성과 효율성이 향상된 임베디드 소프트웨어를 개발할 수 있도록 여러 가지 팁과 기술을 설명했다. 이를 위해 공표된 많은 가이드라인과 상업적인 툴들을 참고했으며, 이에 부가적인 관점과 기능도 제시하고자 노력했다.
이 글이 숙련자나 비숙련자 모두에게 빠르게 변화하는 기술 환경에서 스타일 가이드라인을 개발하고 갱신하는 데 조금이나마 도움이 될 수 있었기를 바란다.
모델 스타일 가이드라인과 양산 코드 생성에 대한 팁과 기술에 대해 더 알고 싶으면 필자에게 연락주기 바란다.
각주1) 논문 “COTS를 사용한 성공적인 전사적 모델과 시뮬레이션을 위한 전략”12
각주2) 비스테온은 SAE 2003 논문에서 데이터 사전(data-dictionary)를 통한 모델 기반 설계의 적용 방법을 설명하였다.13
각주3) 고정소수점 코드와 관련된 오버플로우/언더플로우 파라미터와 다른 팀들의 영향은 “고정소수점 팁”이라는 유명한 MATLAB 중앙 출판에서 확인할 수 있다.
AEM(오토모티브일렉트로닉스매거진)
<저작권자 © AEM. 무단전재 및 재배포 금지>


