2008-04-11 / 10월호 지면기사
/ 앤디 그릿(Andy Gryc) / QNX Software Systems, agryc@qnx.com
복잡한 임베디드 시스템을 경험해 본 사람이라면 누구나 흥분과 걱정이 섞인 최종 통합 과정을 기대한다. 그간의 노력한 작업이 실현되는 순간을 보는 흥분과 이 마지막 순간에 가장 어려운 문제들의 일부가 갑자기 드러나게 될 것이라는 걱정이 교차된다.
문제 정의
핸즈프리 모듈은 블루투스를 이용하여 운전자의 핸드폰과 접속을 한다. 그 후 마이크와 차량 내의 스피커를 이용하여 운전자는 상대편과 통화를 하게 된다. 그림 1은 이러한 과정에서 데이터의 흐름을 보여주고 있다1:
1 몇몇 시스템은 (예를 들어 OnStar) Bluetooth 핸드폰 대신 내부 장착된 전화를 사용한다. 그러나 동작에 있어서 유사하다고 할 수 있다.
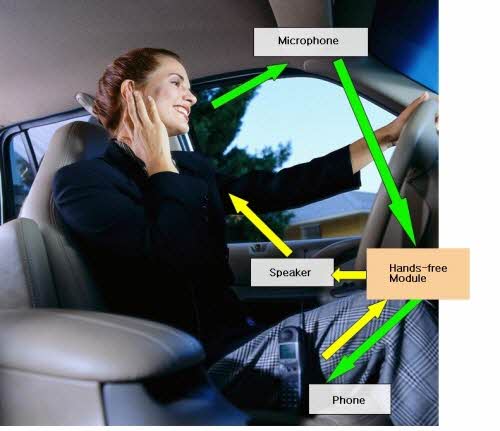
[그림 1] 핸즈프리 핸드폰 시스템
• 초록색 화살표 - 이 화살표는 출력 오디오 경로를 나타낸다. 출력 오디오는 이 경로를 따라 운전자로부터 상대편에게 전해진다. 운전자는 후방 거울에 장착되어 있는 마이크에 이야기를 하고, 이 마이크는 핸즈프리 모듈에 직접 연결되어 있다. 이 모듈은 블루투스 핸드폰과 통신을 하고 전화가 연결된 후에 출력 오디오를 블루투스 폰에 전달하게 된다. 이 휴대폰은 다시 오디오를 상대쪽 전화를 받는 사람에게 전달한다.
이러한 전송 과정에서 마이크가 스피커로부터 나온 음성 출력을 받게 되는 과정에서 문제의 복잡성이 발생하게 된다. 만약 이러한 음성 출력이 수정되지 않을 경우, 이러한 상황은 음성 신호의 회귀 루프(feedback loop)를 만들게 된다. 핸즈프리 모듈은 이러한 결과로 발생하는 에코, 즉 상대편 음성 신호가 스피커를 통해 다시 마이크로 입력되어 발생되는 에코를 없애주어야만 음성 신호는 잘못된 피드백으로 섞이지 않게 된다. 마이크는 도로에서 발생하는 소음이나 회전 깜박이 신호, 외부 바람이나 차창 서리방지용 팬 소리, 차량 내부에서 발생하는 음향 에코, 그 외 다양한 소리를 입력으로 받아들일 수 있다. 핸즈프리 모듈은 이러한 소음이나 잡음을 모두 또는 일부를 제거하고 처리해야만 한다. 또한 음질을 향상시키거나 대화 중 음성의 이해도를 높이기 위해서 핸드폰으로부터 들어오는 오디오에 신호 처리하는 과정을 거칠 수 있다.
사례
핸즈프리 시스템의 주요 특징적인 사항들을 잘 표현하는 예를 만들어보자. 다음은 이를 바탕으로 실험이 가능한 시뮬레이션을 만들 것이다.
일단 우리는 표 1에서 정리된 일련의 태스크를 정의할 것이다. 이러한 태스크들과 그에 할당된 CPU 퍼센트 할당량은 반드시 실제 핸즈프리 시스템의 모든 특성을 정확히 반영할 필요는 없다. 그러나 우리의 모델링 목적에 필요한 기본적인 요소들을 제공할 것이다.
테이블은 각 태스크의 실시간 요구사항을 나타낸다. 우리는 이러한 정보를 시뮬레이션을 설계하는 데 이용할 것이다. 이 문제 도메인에서, 실시간 반응 시간은 10msec~50msec로 한다.
[표 1] 핸즈프리 예제를 위한 태스크 리스트
데이터 흐름
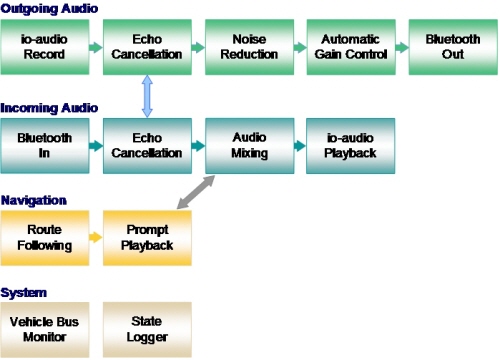
그림 2를 보면, 이 시스템의 데이터 흐름이 4개의 서브시스템으로 나누어 분산되어 있음을 알 수 있을 것이다:
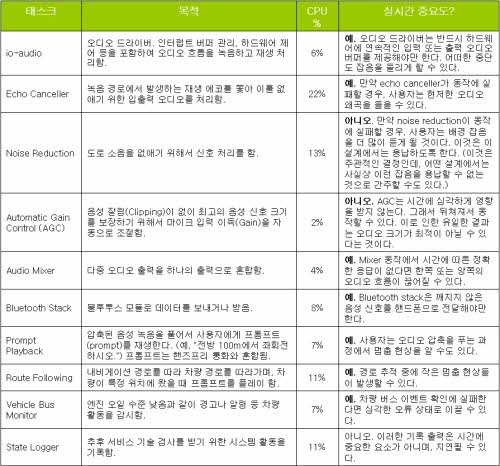
모든 태스크는 총 91%의 CPU를 사용한다. 그러나 모든 태스크들이 동시에 CPU를 필요로 하지 않기 때문에 우리는 여전히 정상적으로 동작하는 시스템을 설계할 수 있어야 한다. 여기에 도전이 될만한 것은 시스템이 많은 부하가 걸릴 때조차도 정상적으로 동작할 수 있는 구조를 만드는 것이다.
[그림 2] 핸즈프리 예제 데이터 흐름
• 출력 오디오 - 운전자의 음성을 녹음하는 마이크로부터 시작해서, 출력 오디오는 Echo Cancellation, Noise Reduction, Automatic Gain Control, Bluetooth 태스크까지 흘러간다. 그런 후 데이터는 핸드폰으로 전해지고 궁극적으로는 원거리에 있는 상대방에게 흘러간다.
시뮬레이션 모델
우리는 핸즈프리 예를 시뮬레이션 하기 위해서 QNX® Neutrino® RTOS 하에 하나의 틀을 만들 것이다. 그 예에서 위에 제시한 각각의 태스크는 독립된 프로세스로 할당될 것이며, 각 프로세스는 매우 간단히 작성될 것이다. 즉 하나의 쓰레드를 가지며, 표 1에서 제시된CPU %의 비율로 CPU를 사용하게 될 것이다.
우리는 실제 시스템에서 발생할 수 있는 여러 가지 특성들을 찾아내고자 한다:
• 실제 시스템에서 데이터를 받아들이는 태스크는 갑자기 발생한다. 다시 말해 처리해야 할 버퍼가 존재할 경우 CPU를 100% 사용하고자 하지만, 그렇지 않은 경우는 쉬는 상태로 있을 것이다. 우리는 이러한 특성을 모방하고자 한다.
모든 태스크에 대해서 우리는 하나의 프로세스를 만들고, 그것을 한번 Spawn 할 것이다. 만약 그 프로세스가 데이터 수요자라면, 동작을 하기 전에 특별한 데이터 공급자로부터 데이터를 기다릴 것이다. 우리는 이러한 데이터 공급자와 수요자 간의 관계를 세마포어로 모델링 할 것이다. 하나의 프로세스를 가지고 이러한 태스크를 만들어 내는 것은 각 태스크 우선순위를 조절하는데 용이하며 파티션 구성에 도움을 줄 것이다.
제약 사항
CPU는 좀더 용이한 시스템 통합을 보장한다
쓰레드 모델링을 하지 않고도 당장 다중 처리를 할 수 있는 것처럼 보이는 코드를 작성할 수 있다. 그러나 이러한 접근법은 매우 어려운 방법일 수 있으며 세세하고 조심스러운 설계를 위해 많은 주의를 요구한다. 시간적인 형태로 모든 태스크가 동작하는 것을 보장하기 위해서 다양한 코드 경로를 능숙하지 않지만 조작을 해야 하며, 최적화 할 필요가 있다. 쓰레드를 이용한 프로그래밍은 이러한 문제를 해결하며, 직접 개발하고 있지 않은 태스크에 대해 주의를 하기 보다는 가까이에 있는 문제에 집중할 수 있도록 한다.
어댑티브 파티셔닝(Adaptive Partitioning)은 개발자를 위한 단순화와 추상화를 위한 혁신적인 도약을 제공한다. 어댑티브 파티셔닝은 쓰레딩과 우선순위보다 한 단계 높은 레벨에서 존재한다. 또한 시스템 설계자가 서브시스템 개발에 집중할 수 있도록 하게 한다. 이러한 테크닉을 이용하여 시스템 설계자는 분리된 기능 구역, 즉 파티션으로 서브시스템을 묶을 수 있으며 각각의 파티션에 최소 보장되는 CPU 시간을 할당할 수 있다.
그림 3의 간단한 예를 참고하기 바란다. 설계자는 소프트웨어 서브시스템을 4개의 파티션으로 나눌 수 있으며, 각 파티션에 하나의 CPU 예산을 할당한다: User Interface에 20%, MP3 playback에 20%, Hands-free 오디오에 30%, Navigation과 Route Calculation에 30%를 할당한다.

[그림 3] 시스템 설계자가 각 소프트웨어 서브시스템에 CPU 예산을 할당할 수 있는 시간 파티션된 환경에 대한 간단한 예. 시간 파티셔닝은 높은 우선순위의 서브시스템이 낮은 우선순위의 서브시스템의 CPU 시간을 뺐지 못하도록 한다.
사실상, 파티셔닝은 하나의 프로세서를 작은 “가상”의 CPU로 나눈다. 그렇게 함으로써 다중 소프트웨어 서브시스템을 통합하는 일을 단순화 한다. 개발자로서 서브시스템 외부의 쓰레드 우선순위에 대해서는 걱정할 필요가 없다. 그러한 쓰레드는 비록 높은 우선순위로 동작하고 있을 지라도 현재 쓰레드에 영향을 주지 않는다. 더욱이 시스템 설계자에 의해 정의된 CPU 예산 내에서 동작하는 지를 확인하기 위해서 서브시스템을 쉽게 테스트할 수 있다. 통합 단계에서 OS는 각각의 리소스 예산에 보장함으로써 한 서브시스템이 다른 서브시스템에 의해서 필요한 리소스를 소모하지 못하도록 한다. 각각의 시스템은 예측한대로 동작하게 되며 이전에 테스트한대로 역시 동작하게 된다.
우리의 예에서 만든 시뮬레이션 모델을 시뮬레이션 하기 위해서 필요한 소스코드는 다소 간단하다. 다양한 태스크의 구성을 쉽게 하고 CPU 사이클을 소모하는 활동을 시뮬레이션 하기 위해서 명령 창에서 옵션을 받을 수 있도록 한다. 우리는 실제로 데이터 공급자와 수요자 간의 관계를 시뮬레이션 하게 된다.
• 각 요소들 간의 데이터 흐름을 흉내 내기 위해서, 두 개의 서로 통신을 하는 프로세스는 세마포어를 사용한다. 공급자는 세마포어를 설정함으로써 데이터를 만들어내고 수요자는 세마포어를 기다림으로써 그 데이터를 읽는다.
• 실시간 요구사항이 필요한 것으로 표시된 프로세스가 그 처리를 하는 동안 이미 정해진 시간 범위를 벋어나면, 코드는 QNX 시스템에 에러 로그를 기록할 것이다. 이렇게 기록된 에러는 (데이터나 음성, 혹은 시스템이) 깨지는 상황을 시뮬레이션하는데, 이는 특정하게 정의된 범위 내에서 그 프로세스가 작업을 마칠 수 없음을 나타내는 것을 의미한다.
리스트 1은 시뮬레이션을 하기 위한 소스코드를 포함한다. 이해의 명료함과 간단함을 위해서 에러 확인 부분은 제거되었다. 만약 전체 버전의 소스를 원한다면, 저자에게 요청하기 바란다.
// simmod.c : Simulation Module
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
int report_real_time_violations = 0; // Non-zero means report deviations from real-time
int time_window_ms = 0; // Length (ms) between each burst of activity
int cpu_percent = 0; // How much CPU will we chew up?
char process_name[256];
char consume_name[256];
char produce_name[256];
sem_t *consume_semaphore;
sem_t *produce_semaphore;
[리스트 1] simmod.c 시뮬레이션 모듈 소스
uint64_t timediff_ms(struct timespec *start, struct timespec *stop)
{
uint64_t stop64 = (uint64_t)stop->tv_sec*1000 + (uint64_t)stop->tv_nsec/1000000;
uint64_t start64 = (uint64_t)start->tv_sec*1000 + (uint64_t)start->tv_nsec/1000000;
return stop64-start64;
}
void processLoop()
{
struct timespec start;
struct timespec busyloop;
struct timespec now;
uint64_t delta;
clock_gettime(CLOCK_REALTIME, &start);
// If we`re a consumer, wait for something to consume
if (consume_semaphore) {
sem_wait(consume_semaphore);
}
// Run a busy loop to use up our alloted CPU time
clock_gettime(CLOCK_REALTIME, &busyloop);
do {
clock_gettime(CLOCK_REALTIME, &now);
delta = timediff_ms(&busyloop, &now);
} while (delta < (time_window_ms*cpu_percent)/100);
// If we`re a producer, produce our data
if (produce_semaphore) {
sem_post(produce_semaphore);
}
// Have we overrun our real-time window?
if (consume_name[0]) {
int timeout = 10; // We wait a maximum of 10 seconds for a semaphore to be startd...
int err = 0;
do {
consume_semaphore = sem_open(consume_name, 0);
if ((int)consume_semaphore==-1) {
err = errno;
sleep(1);
fprintf(stderr, ".");
} else {
err = 0;
}
} while (err!=0 && --timeout > 0);
}
}
void processArguments(int argc, char *argv[])
{
int arg;
while(( arg = getopt( argc, argv, "n:c:p:u:t:rh")) != EOF) {
switch ( arg ) {
case `n`:
strcpy(process_name, optarg);
// QNX-specific non-POSIX thread setname so we can track names in System Profiler
pthread_setname_np(pthread_self(), process_name);
break;
case `c`:
strcpy(consume_name, optarg);
break;
case `p`:
strcpy(produce_name, optarg);
break;
case `u`:
cpu_percent = atoi(optarg);
break;
case `t`:
time_window_ms = atoi(optarg);
break;
case `r`:
report_real_time_violations = 1;
break;
case `h`:
printf("simmod \n");
printf("Options:\n");
printf("\t-n X\tName of this module\n");
printf("\t-c X\tConsume from semaphore X");
printf("\t-p X\tProduce to semaphore X");
printf("\t-r\tRealtime; report any failures to get enough time");
printf("\t-u X\tUse X%% of the CPU");
printf("\t-t X\tTime window is X milliseconds");
break;
default:
exit(EXIT_FAILURE);
}
}
}
int main(int argc, char *argv[])
{
processArguments(argc, argv);
openSemaphores();
while (1) {
processLoop();
}
return EXIT_SUCCESS;
}
Simmod 시뮬레이션 프로세스는 여러 가지 명령 옵션을 가지며, Spawn이 될 수 있다. 우리는 시뮬레이션에서 태스크의 부하를 가상으로 만들어내기 위해 이러한 옵션을 사용할 것이다.
-n name
프로세스의 이름. 이 옵션은 시스템 프로파일러 추적에 있어서 그 프로세스의 서로 다른 사용 예를 추적하는 것을 가능하게 한다.
-p name
공급자 세마포어의 이름. 공급자 프로세스는 이름으로 명기된 세마포어 (named semaphore, 이하 명명 세마포어)를 설정함으로써 데이터를 쓰게 “write” 된다.
-c name
수요자 세마포어의 이름. 수요자 프로세스는 명명 세마포어를 기다림으로써 데이터를 잃게 “read” 된다.
-u cpu_time
사용될 CPU 시간의 양. 프로세스는 가능한 처리 사이클의 퍼센트를 소모하면서 바쁜 처리 루프를 돌아가게 된다.
-t time_window
프로세스의 처리 시간 범위. 프로세스는 millisecond 단위로 데이터를 처리하게 된다. 우리는 오디오 연결 흐름을 처리하는 프로세스를 위해서 낮은 값(30ms)을, 오디오와 관련되어 있지 않은 요소를 위해서는 높은 값(150ms 또는 500ms)을 설정할 것이다.
-r
우리가 설정한 실시간 마지노선을 넘어설 경우 실패를 기록하도록 함. 만약 프로세스가 적절한 시간 범위 내에서 주 루프의 바닥까지 도달하지 못할 경우, 프로세스는 시스템 로그에 실패를 기록하게 된다. 이때 주 루프는 비지 루프(Busy loop)와 수요자 세마포어 대기로 구성된다. 이러한 방법을 사용함으로써, 우리는 이 시뮬레이션에서 설정된 실시간 목표를 만족하지 못하는 경우를 기록하여 좇아갈 수 있다.
clock_gettime(CLOCK_REALTIME, &now);
delta = timediff_ms(&start, &now);
if (report_real_time_violations && delta>time_window_ms) {
// Report error with slog (don`t intermix output from multiple failing components)
slogf(_SLOG_SETCODE(_SLOGC_TEST, 0), _SLOG_WARNING,
"%s exceeded time window by %d ms.\n", process_name, (int)(delta-time_windo
_ms));
} else {
// Sleep for the rest of the window to emulate blocking,
// unless we`re a consumer, in which case we`re throttled by the producer
if (!consume_semaphore) {
// POSIX guarantees *at least* the amount that you sleep for, but usually
// more since it is a multiple of time slice and rounded up. We compensate
// for this by subtracting a small amount in what we sleep. After all, we`re
// not being driven by a hardware interrupt, as a real system would be.
delta = time_window_ms - delta - 10;
if (delta > 0)
usleep(delta * 1000);
}
}
}
void openSemaphores()
{
if (produce_name[0]) {
produce_semaphore = sem_open(produce_name, O_CREAT, S_IRWXO, 0);
} 어댑티브 파티셔닝은 CPU가 효율적으로 사용되고 있지 못하는 경우와 시스템이 유휴시간(Idle Time)을 갖는 것을 확인한다. 그 결과로 현재 바쁘지 않은 파티션에서 여분의 처리시간을 가진다면 좀더 효율을 얻을 수 있는 파티션으로 동적으로 CPU 사이클을 할당할 수 도 있다. 이러한 접근법은 시스템의 CPU 요구가 최고 일 때, 최대 100% CPU 활용을 가능하게 한다.
시스템 설계자는 또한 각각의 파티션에 독립된 메모리 예산을 할당할 수도 있다는 것을 확인할 필요가 있다. 그렇게 함으로써 각 서브시스템은 항상 요구된 태스크를 구동하기 위해서 충분한 메모리를 가질 수 있게 한다. 이 기고는 시간 파티셔닝에 대해서만 초점을 맞추고 있지만, 메모리 파티셔닝도 통합 과정의 노력을 단순화하는 데 유용한 기술을 제공한다.
태스크 시뮬레이션
전통적인 실시간 운영체제에서는 단지 우선순위를 사용함으로써 어떤 쓰레드가 동작할 지 제어한다. 단순히 말하면, 낮은 우선순위의 쓰레드에 앞서 높은 우선순위의 쓰레드가 동작하게 된다. 만약 동일한 우선순위의 쓰레드가 동작할 준비가 되어 있다면, 쓰레드 스케줄링 정책이 어떤 쓰레드가 수행될 지를 결정한다. 단순화하기 위한 목적으로 우리는 가장 공평한 스케줄링 정책을 Round-robin으로 가정할 것이다. Round-robin 스케줄링에서는 블록이 되기 전까지 수행되거나, 정해진 시간 단위(Timeslice)를 모두 소모하거나, 높은 우선순위 쓰레드에 의해 선점(preempt)된다. 일단 쓰레드가 가지고 있던 시간 단위를 모두 소모하면, 동일한 우선순위의 Ready Queue에 준비된 다음 쓰레드에 의해 선점되어진다.
문제는 쓰레드 우선순위는 완전히 우리가 요구하는 특성을 반영하지 못한다는 것이다. 예를 들어 Echo cancellation 태스크는 높은 우선순위이고 Noise reduction 태스크는 낮은 우선순위이다. 각각 30과 10의 우선순위를 할당하는 것은 Echo cancellation 작업이 완전히 끝나도록 하며, Noise reduction에는 남아있는 CPU를 줄 것이다. 그럼에도 불구하고, Echo Cancellation 태스크는 너무 많은 CPU를 소모해서 Noise reduction 태스크가 동작하지 못하게 만들어서는 안된다. 그것은 Noise reduction 태스크가 같은 데이터 흐름에 있으며, 그 태스크에서 발생하는 어떠한 지연 현상도 그와 관련된 다음 태스크에 영향을 줄 것이기 때문이다. 출력 오디오 흐름에 있는 각각의 태스크는 그 전의 태스크에서 오는 데이터에 의존하게 되며 각각은 녹음 원에서부터 핸드폰 출력까지 오디오 데이터가 흘러갈 수 있도록 동작할 필요가 있다.
이론상으로 동일한 우선순위를 모든 태스크에 부여함으로써 모든 태스크가 동작하는 것을 보장할 수 있을 것이다. 그러나 그러한 접근법이 동일하지 않은 시스템 처리과정 요구는 보호하지 못한다. 즉 우선순위 모델 단독으로는 시스템 요구사항을 만족시키는 것을 어렵게 한다.
• 또한 우리는 데이터를 소모하지 않는 프로세스는 다소 일정한 상태로 CPU를 소모한다고 가정한다.
• 우리는 시스템이 적절히 잘 설계되고 충분한 CPU를 얻는지 알고자 한다. 그래서 쓰레드를 각각의 실시간 요구사항에 민감하도록 만들 것이다. 만약 한 프로세스가 실시간 민감하다고 표시되면, 우리는 요구된 시간 내에 작업을 수행하지 못할 때 어떤 경우라도 기록을 할 것이다. 물론, 실시간 요구사항은 전후 상황(Context)에 의존적이다. 어떤 시스템의 경우 10msec의 지연시간이 받아들여질 수 있으나 어떤 경우는 심각한 문제를 초래한다. 우리의 예에서는 50ms 이하의 지연 요구사항은 모두 실시간으로 고려한다. • 입력 오디오 - 핸드폰과 Bluetooth 연결로부터 시작해서, 입력 오디오는 Echo Cancellation을 통해 Audio Mixing 태스크까지 흘러가는 데, 그 과정에서 필요에 따라 프롬프트 재생으로부터 나온 오디오와 혼합될 수 있다. 그런 다음 오디오 데이터는 드라이버를 거쳐 차량 스피커로 나오게 된다. Echo Cancellation 태스크 내 두 부분은 서로 데이터를 교환해야 하는데(파란색 화살표), 이 시뮬레이션에서 그러한 특성을 모델링 할 필요는 없을 것이다.
• 내비게이션 - 내비게이션 엔진은 다음 이동 지점에 도착할 때, “다음 신호등에서 오른쪽 방향입니다”와 같은 오디오 프롬프트를 압축 해제한 다음 재생하도록 Prompt Playback 태스크에 명령을 보낸다. Audio Mixing과 Prompt Playback은 서로 데이터를 교환해야 하는데(회색 화살표), 여기에서는 그러한 특성을 모델링 할 필요는 없을 것이다.
• 시스템 - 이러한 태스크는 시스템의 나머지 부분과 서로 상호작용을 하지 않는 독립적인 기능들로써 동작한다.
핸즈프리 신호 처리 알고리즘은 전형적으로 엄격한 시간지연에 대한 요구사항을 만족시켜야 한다. 예를 들어 알고리즘이 30 msec 내에 신호를 처리할 수 없다면, 처리 중 발생하는 인공적인 소리가 사용자에게 들리게 될 수도 있을 것이다. 지연시간이 길어지면 길어질수록 좀더 심각한 음성 신호 왜곡이 발생하게 된다. 더욱이 보통 핸즈프리 모듈은 오디오 처리 이상의 일을 한다는 것인데, 예를 들어 다음과 같은 일을 수행해야만 한다.
• 차량 내의 다른 모듈에서 보내지는 메시지를 처리하거나 기록하기 위해서 차량 버스를 감시하는 작업
• 교통정보를 위해서 전송된 디지털 라디오를 스캔하는 작업
• 내비게이션 경로를 따라가는 작업
핸즈프리 통화 중에 이러한 다른 태스크를 동시에 처리하는 일은 일시적으로 오디오 흐름을 막아 통화중인 사용자가 갑작스럽게 “퍽”하는 소리나 잡음을 듣게 될 수도 있다. 일반적으로 이러한 문제에 대한 해결책은 DSP(Digital Signal Processor)를 둠으로써 음성 신호처리에 부하를 덜어주는 것이다. 그러나 이러한 접근법은 시스템 설계를 복잡하게 할 수 있으며, 또한 부품 비용의 증가로 제품 단가를 높이는 결과를 낳게 된다. 또 다른 대안으로 시스템 설계자는 QNX® Neutrino® RTOS와 같은 실시간 운영체제를 사용하여 범용 프로세서가 엄격한 시간지연 요구사항을 가진 신호처리 알고리즘을 포함하여 많은 태스크를 동시에 처리하게 함으로써 이러한 문제를 해결할 수도 있다. 이러한 방법은 시스템 설계자가 전체 시스템의 가격을 낮추고 핸즈프리 시스템에 기능을 추가하는 것을 가능하게 한다.
• 노란색 화살표 - 이 화살표는 입력 오디오 경로를 나타낸다. 핸드폰은 상대편으로부터 전송된 오디오를 핸즈프리 모듈에 전달하며, 핸즈프리 모듈은 이 오디오를 자동차의 스피커에 전달한다. 그 모듈은 차량 오디오 시스템과 MOST(Media Oriented Systems Transport) 같은 자동차 네트워크 버스를 통해 연결되거나 직접 바로 연결되기도 한다.
비록 개발팀이 매우 조심스럽게 각각의 소프트웨어 요소들을 설계하고 코딩을 했다고 할지라도 충분히 함께 테스트 되지 못한 각 요소들 간에는 복잡한 상호작용들이 발생할 수 있다. 특히 그러한 요소들은 CPU 시간의 부족 현상(Starvation)을 만들 수 있으며, 이로 인해 원치 않고 이해하기 힘든 다양한 현상들이 시스템에 발생하게 된다. 그러한 문제는 일반적으로 고통스럽게도 마지막까지 숨어 있다가 나타나 개발팀이 쉽게 해결책을 찾기 힘들며 많은 시간을 소모하게 한다.
치밀한 시스템 설계자라면 다양한 설계 블록에 대한 밉스(MIPS: million instructions per second)를 예상하여 이에 대한 합계로 전체 처리 능력을 예측했을 것이다. 그러나 이러한 방법은 완전하지 않으며, 단지 가능한 방법 중 하나일 뿐이다. 불행히도 이 방법은 CPU 사용량의 최고점이나 갑작스런 증가를 설명하지 못한다. 이와 같이 여러 개발자들의 최선의 노력에도 불구하고 시스템을 혹사시켜 끝내 작게는 삐걱거리는 HMI(Human Machine Interface)에서 크게는 전체 시스템의 멈춤 현상까지 다양한 결과로 나타나게 된다.
이 문제에 대한 해결책은 코드 최적화에서 시스템 재설계까지 다양한 방법으로 얻을 수 있지만, 이러한 방법들은 이미 촉박한 제품 일정에 압박감을 더하게 된다. 이 기고에서 우리는 실제 텔레매틱스 시스템에서 발생할 수 있는 시스템 통합 문제를 검토하고, 여러 가지 해결책을 시도할 수 있는 시스템 틀(System Mockup)을 고안할 것이다. 이 시스템 틀을 사용하여 우선순위 기반 쓰레드 스케줄링(Priority-based thread scheduling)의 장단점을 확인하고, 어떻게 어댑티브 파티셔닝(Adaptive Partitioning)이 어떻게 이러한 단점을 해결하고, 이미 설계를 마친 디자인에서 쓰레드의 CPU 부족 현상을 막을 수 있는지, 그리고 보다 향상된 CPU 최적화를 가져다주는지 확인할 것이다.
AEM(오토모티브일렉트로닉스매거진)
<저작권자 © AEM. 무단전재 및 재배포 금지>





